News & press releases
New energy-efficiency developments in XiTAO, OmpSs@FPGA and FPGA Undervolting
As the LEGaTO project nears its completion, we examine how the main goals of energy efficiency have been achieved. In this column, we explore the techniques that have been implemented in the toolchain back-end (runtime library system) and describe the achievements in contrast to prior approaches. We focus on heterogeneous scheduling techniques implemented as part of the moldable XiTAO C++ library, and discuss the energy reduction that is enabled by the usage of FPGA. We report both scheduling approaches integrated into OmpSs@FPGA as well as FPGA undervolting with controllable error rates.
Energy efficiency in XiTAO
Modern compute platforms are increasingly heterogeneous. This encompasses platforms with asymmetric cores -such as big.LITTLE- and platforms composed of CPUs, GPUs and FPGAs. Schedulers for asymmetric cores have traditionally taken a very simplistic approach whereby performance critical applications are mapped on big cores and less critical ones are mapped to slower, yet more energy efficient cores. In the context of parallel applications, the scheduling problem is more complex, as different tasks in the same application may be scheduled on a set of cores of one type, while other tasks could be scheduled on cores of the same or different type. Within LEGaTO, we have researched novel schedulers for task-based applications that minimize energy consumption on heterogeneous platforms.
A core observation that motivates our design is that different task types achieve peak efficiency on different core configurations. Figure 1 shows this behavior. The figure shows the energy required for executing two different types of tasks (matrix multiplication and memory copy) on the Denver and A57 cores that are present on an Nvidia TX2 development board. Interestingly, while matrix multiplication is most efficient on two Denver cores, the matrix copy is most efficient when executed on a single A57 core.
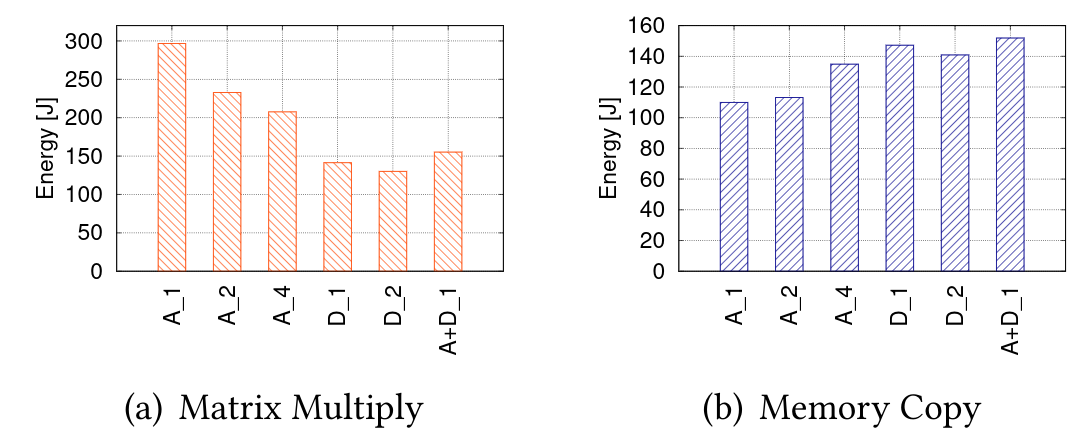
Figure 1: Energy of two kernels on the TX2 platform as a number of core type (A: A57, D: Denver) and number of cores (A_1..A_4). A+D_1 has one A57 core and one Denver core
To this end, methods to model task performance and task power consumption at runtime are required. To achieve this, we are extending LEGaTO's moldable XiTAO C++ work stealing library with a plugin architecture as shown in Figure 2. This architecture allows the runtime scheduler to query task performance predictions and power profiles on a per-task basis. The scheduler then uses this information to minimize the energy execution for each task, individually. Finally, to limit the power consumption of idle cores participating in work stealing, we have implemented an exponential back-off scheme that reduces the activity of idle workers by putting them to sleep for increasingly long periods, up to a maximum.
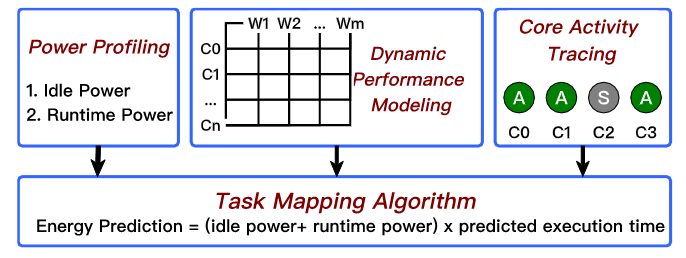
Figure 2: Plugin-architecture developed for XiTAO
To validate the approach, we execute the runtime scheduler (called LENC: "Lowest Energy without Criticality") on both the TX2 and on a multicore Intel platform and compare with various scheduling alternatives. Both platforms provide different energy modeling methodologies. Our results over three applications (VGG-16, Heat and SparseLU) show that LENC achieves an energy reduction ranging from 31% to 75% compared to a work stealing scheduler (RWS) that is completely agnostic to task types and moldability, as seen in Figure 3.
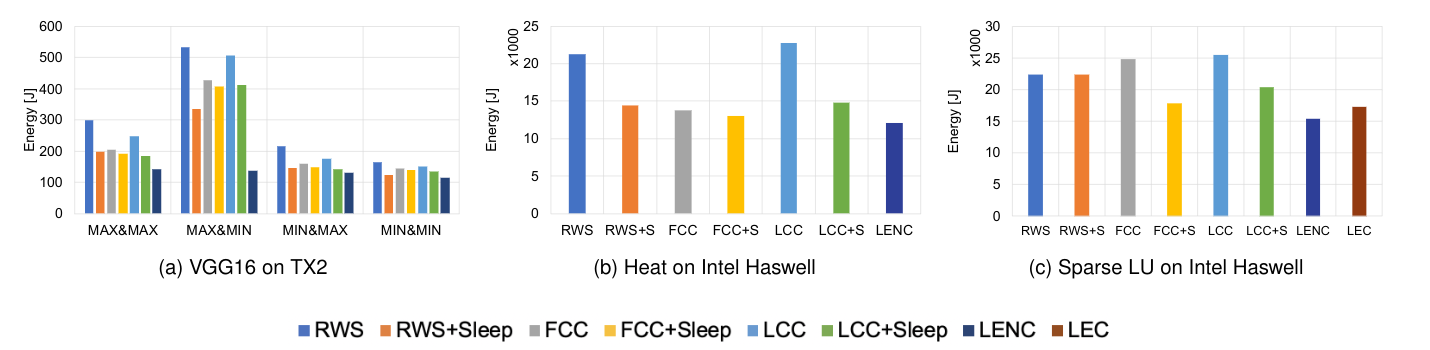
Figure 3: Energy reductions enabled by the LENC scheduler
OmpSs@FPGA: efficiency with productivity
We have executed a set of matrix multiplication experiments in the Xilinx ZCU102 development kit, with 4 ARM A53 cores and an integrated XCZU9EG FPGA. Each matrix multiplication experiment consists of 20 executions of matrix multiply, on a matrix of 2816x2816 single precision floating point elements. The matrix is blocked in tiles of 256x256 values.
The program uses OmpSs to offload tasks, either to the FPGA or the ARM cores. The FPGA is programmed through OmpSs to have 3 instances of the matrix multiplication IP core, that can be used in parallel, and independently of each other.
Figure 4 shows the power consumption of the execution of 7 experiments, in this order:
- the two first peaks reaching up to 18W (between seconds 17-33 and 49-65), are two executions of the 20 matrix multiplications, using the 3 instances of the matrix multiplication IP core.
- the next two peaks reaching 14W (between seconds 75-97 and 110-129) are two executions of the 20 matrix multiplications, using 2 of the IP core instances.
- the next two sets of bars reaching 10.5 - 11W (seconds 141-200 approximately) are the same two executions of the 20 matrix multiplications, using a single of the IP core instances.
- the final flat line stable at 3W is the same execution of the 20 matrix multiplications using the 4 ARM A53 cores only. In this last execution, we have substracted the power consumption of the PL logic (around 3.8W while idle), as it is not used in the execution.
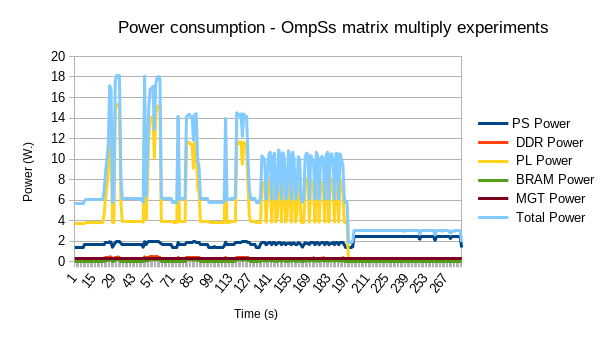
Figure 4. Power Consumption
The figure shows the total power consumption (light blue line), the Processing System (PS) power (dark blue), and the Processing Logic (PL) power (yellow), as the main contributors. DDR, BRAM, and Management power consumptions are constantly below 0.5W.
If we compute the GFlops obtained by the different sets of executions, we get:
- 3x IP core instances achieve 94.5 Gflops, with a mean consumption of 15.1W and a maximum of 6.26 GFlops/W.
- 2x IP core instances achieve 77.6 Gflops, with a mean consumption of 10.6W and 7.32 GFlops/W. This is the nest energy-efficient experiment.
- 1 IP core instance achieves 47.1 Gflops, with a mean consumption of 9.2W and 5.11 GFlops/W.
- 4 ARM A53 cores achieve 12.1 Gflops, with a mean consumption of 2.95W, and 4.1 GFlops/W.
Concluding, the code transformations done with OmpSs to exploit matrix multiplication on the FPGA result in an increase of the GFlops/W obtained from the Zynq U+ chip, increasing power efficiency when using more resources in the FPGA fabric.
FPGA Undervolting: beyond energy efficiency with controlled error rates
The power consumption of a modern chip, including FPGAs, depends on temperature. Temperature affects static power consumption. As the external temperature increases, the leakage current and, in turn, the leakage-induced static power increases. As technology node size reduces, a large fraction of power consumption comes from the static power. Therefore, temperature has a larger effect on the power consumption of denser chips. On the other hand, temperature can have a considerable effect on circuit latency.
To understand the combination of multiple effects mentioned above, one must study the effect of the environmental temperature on the power-reliability trade-off of FPGA-based CNN accelerators under reduced-voltage operation. To this end, we use Xilinx´s DNNDK accelerator; utilize GoogleNet as a benchmark and undervolt VCCINT, which is the voltage rail associated with the FPGA computational resources. To regulate the FPGA temperature, we control the fan speed using the PMBus interface. We also use the same PMBus interface to monitor the on-board live temperature. By doing so, we can test different ambient temperatures ranging from 34◦C to 52◦C degrees.
Figure 5 depicts the power consumption of the FPGA when executing GoogleNet with different VCCINT values at different temperatures, the nominal VCCINT is 850mV. Clearly, temperature has a direct effect on power consumption. As temperature increases, power consumption proportionally increases. This is due to increase in static power when the chip heats up. Dynamic power consumption is also affected by temperature, but this effect is almost negligible. Importantly, we observe that the effect of temperature on power consumption reduces for lower voltages. For example power change from 34◦C to 52◦C are 0.46% and 0.15%, respectively at VCCINT = 850mV and VCCINT = 650mV.
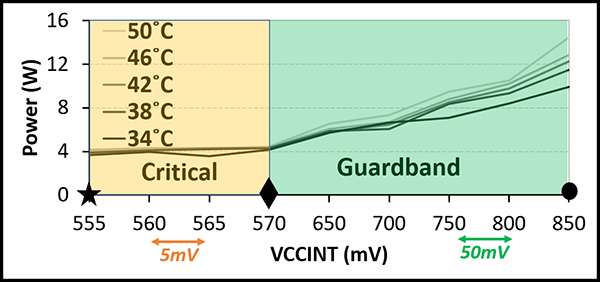
Figure 5: Googlenet: Temperature and Power
Figure 6 shows the effect of temperature on the accuracy of the reduced-voltage CNN accelerator. Our experiment demonstrates that higher temperature at a particular voltage level leads to higher CNN inference accuracy. This is because at higher temperatures, there are fewer undervolting related errors due to decreased circuit latency, an artifact due to the Inverse Thermal Dependence (ITD) property of contemporary technology nodes.
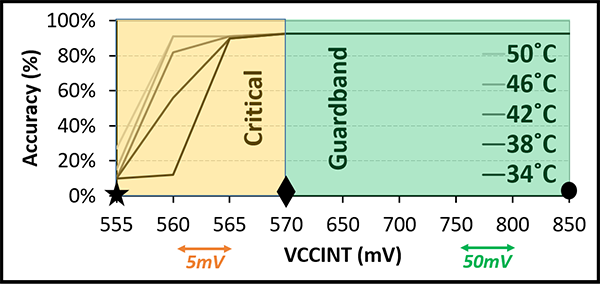
Figure 6: Googlenet: T and inference accuracy