News & press releases
XiTAO - Nanos Runtimes Integration
The XiTAO - Nanos integration is at the core of the LEGaTO toolset objectives in order to achieve the goals of energy efficiency. The LEGaTO programming model (OmpSs) currently uses Nanos under the hood. For end-user applications to leverage the energy-aware features that are being developed in the XiTAO research runtime, it is necessary that Nanos and XiTAO share and exchange execution resources in a coordinated manner.
The Integration
XiTAO and Nanos are both task-based runtime systems that offer different features targeting energy-efficient scheduling on heterogeneous hardware. Thanks to the newly developed integration between the two runtimes, XiTAO and Nanos are able to orchestrate their resource usage by assigning a set of CPU resources to each runtime exclusively (as shown in Figure 1). Prior to the integration, the runtimes would need to acquire exclusive access to the underlying hardware to eliminate resource sharing, which was both limiting and inefficient in terms of performance and energy.
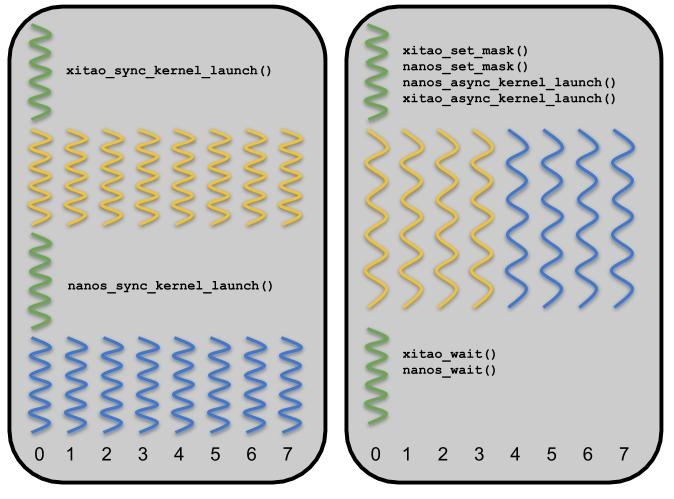
Figure 1: Exclusive access vs. resource-managed access of XiTAO and Nanos runtime
The Outcome: Interference and Energy Aware Scheduling
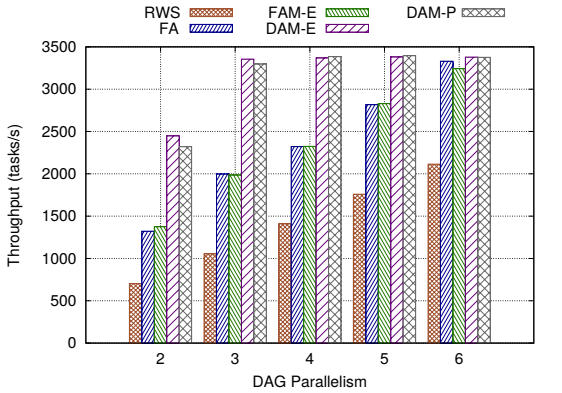
Among multiple outcomes, the integration enables interference and energy-aware scheduling. Applications that share resources are bound to suffer from interference, i.e.~a variation in the processor performance that is observed as dynamic performance asymmetry. The XiTAO task scheduler dynamically learns the performance characteristics of the underlying platform and uses this knowledge to schedule around dynamic performance asymmetry. The scheduler is evaluated using both micro-benchmarks and real benchmarks. Figure 2 shows the throughput performance with background interference on a selected benchmark.
In addition, the ability to dynamically characterize the system allows for energy-efficient scheduling. Hence, the scheduler is able to, on a per-task basis, estimate the energy consumption and take task placement decisions to reduce the overall application energy consumption. Using an offline CPU power model of different task types, power profiles that are used at runtime to estimate per-task energy consumption are constructed based on a prediction of the task execution time. The evaluation results show that the scheduler achieves the lowest energy in all cases, and the lowest EDP in most cases, compared to a random work stealing scheduler and a performance-only scheduler, independent of the platform's DVFS setting. Figure 3 shows up to three-fold savings in energy when running VGG16 classification deep learning model.
 |
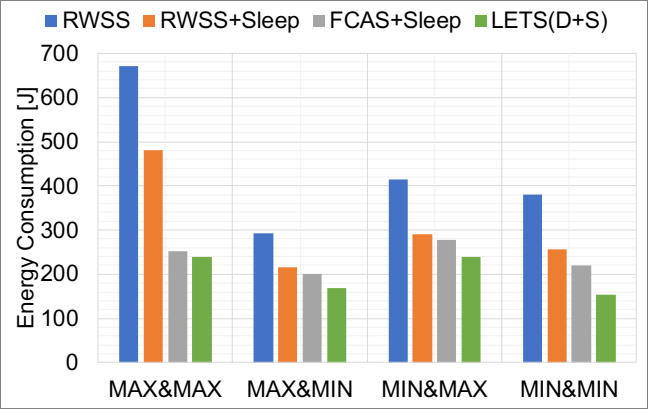 |
| Figure 2: DAM-E and DAM-P show the sustained throughput performance for Matmul benchmark with dynamic background interference | Figure 3: LETS(D+S): The comprehensive energy-aware scheduler tested with VGG16 Darknet benchmark |