News & press releases
Integrating OmpSs and Maxeler infrastructures for FPGA acceleration
In the context of the LEGaTO project, we have performed the integration of two execution environments for FPGA acceleration: OmpSs and Maxeler. We leverage the task management and scheduling of OmpSs with the code generation facilities provided by Maxeler.
The figure below shows the structure of the OmpSs-Maxeler compilation flow and runtime environment. The programmer develops the applications on C/C++ for the OmpSs part, and using the MAXJ – Java-like – language for the computation kernels.
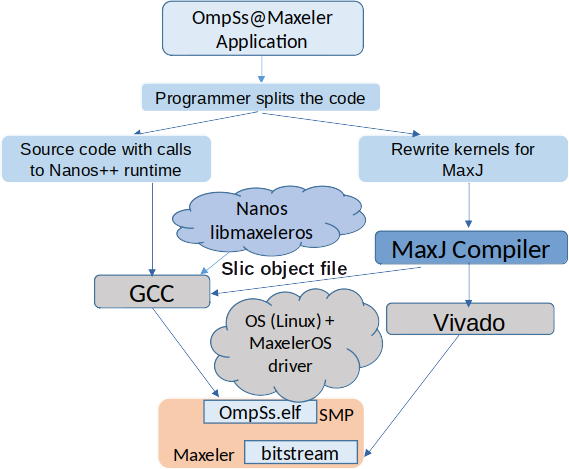
OmpSs-Maxeler integrated ecosystem
Compilation flow
Compilation for the Maxeler device follows the usual toolflow provided by Maxeler. Starting from the MaxJ kernels, MaxCompiler generates the VHDL code, which is later synthesized by the Xilinx Vivado tool to generate the bitstream. Additionally, MaxCompiler generates functions that are callable from C/C++ to initiate data transfers and start the kernels in the Maxeler DFE, using the Maxeler SLiC interface. This is the interface that the OmpSs runtime invokes to start the execution on the DFE.
The OmpSs part of the application is compiled with the CPU compiler (GCC, ICC). During initialization, the SLiC interface is used to register the kernel functions compiled through MaxJ, onto the Maxeler runtime. The Nanos runtime creates a helper thread for each Maxeler DFE present in the system. Once tasks are created using the newly implemented target device plugin for Maxeler support (see below), they are managed by such helper threads. Additionally, when a helper thread finds a task, it connects with the kernel function through the SLiC interface to transfer the data and execute the kernel in the DFE.
Runtime implementation
We have extended the Nanos++ runtime system to support the new target device architecture. This information is contained on a device descriptor, which invokes the Maxeler runtime when needed for the following functionalities:
- Memory allocation: to obtain and manage memory that is accessible from the Maxeler DFE devices.
- Data transfers: to move data in and out of the DFE device, with various flavors, single dimension vectors, 2-dimensional matrices, etc.
- Kernel management: invoking kernels and triggering the data transfers are operations that the Maxeler DFEs accept through attached queues. When the task including the kernel is ready from dependencies, Nanos++ ensures to enqueue first the input data transfers, then the kernel invocation, and finally the output data transfers.
Ongoing development
Our development is ongoing, and there are several topics that will be completed during the development of the project:
- Tuning of the environment: we are currently analyzing the performance of the new environment and tuning it, to improve the use of the SliC interface.
- Improving programmer’s productivity: we are working on providing support for programmers on the decision of which kernels to port to MaxJ from C/C++, in order to improve productivity in application porting.
- Evaluation of the new environment: we have a matrix multiplication benchmark running on the environment, and we plan to port other benchmarks to use it, in order to evaluate the performance obtained and compare it with manually coded versions of the benchmarks.
Find the OmpSs-Maxeler integration here: https://github.com/legato-project/ompss-maxeler